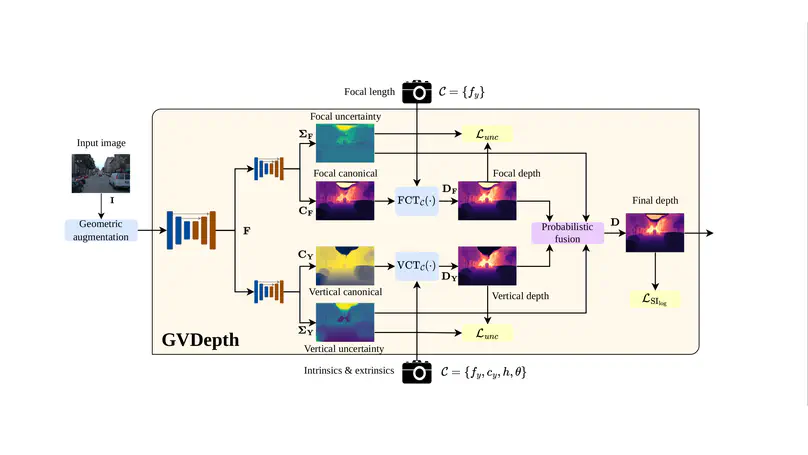
GVDepth leverages novel canonical representation to disentangle depth from camera parameters, ensuring consistency across diverse camera setups. Depth is estimated via probabilistic fusion of intermediate representations stemming from object size and vertical position cues, achieving accurate and generalizable predictions across multiple datasets and camera configurations. Notably, GVDepth achieves accuracy comparable to SotA zero-shot methods, while training with a single dataset collected with a single camera setup.